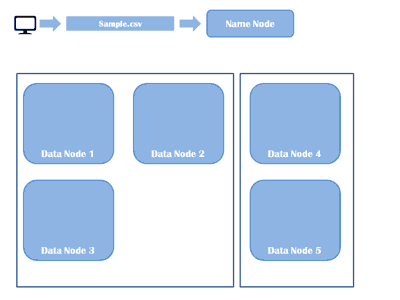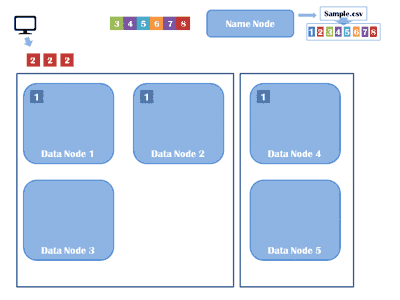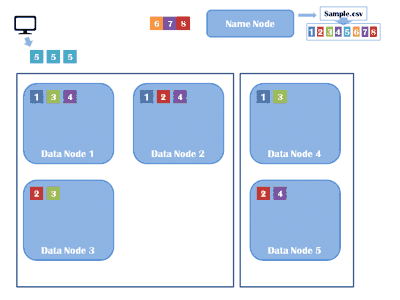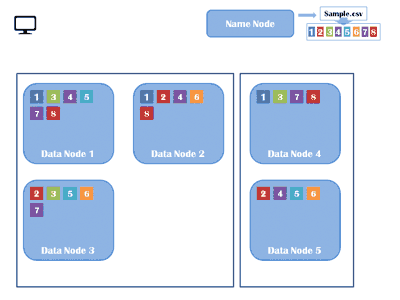
Let’s talk about components of Hadoop. Hadoop as a whole distribution provides only two core components and HDFS (Hadoop Distributed File System – Storage component ) and MapReduce (which is a distributed batch processing framework – processing component ), and a bunch of machines which are running HDFS and MapReduce are known as Hadoop Cluster.
You can add more nodes in Hadoop Cluster the performance of your cluster will increase which means that Hadoop is Horizontally Scalable.
HDFS – Hadoop Distributed File System (Storage Component)
HDFS is a distributed file system which stores the data in distributed manner. Rather than storing a complete file it divides a file into small blocks (of 64 or 128 MB size) and distributes them across the cluster. Each blocks is replicated (3 times as per default configuration – replication factor ) multiple times and is stored on different nodes to ensure data availability in case of node failure. Normally HDFS can be installed on native file systems like xfs, ext3 or ext4 .
You can write file and read file from HDFS. You cannot updated any file on HDFS. Recently Hadoop has added the support of appending content to the file which was not there in previous releases.
Here are some examples of HDFS commands.
Get list of all HDFS directories under /data/
$ hdfs dfs -ls /data/
Create a directory on HDFS under /data directory
$ hdfs dfs -mkdir /data/hadoopdevopsconsulting
Copy file from current local directory to HDFS directory /data/hadoopdevopsconsulting
$ hdfs dfs -copyFromLocal ./readme.txt /data/hadoopdevopsconsulting
View content of file from HDFS directory /data/hadoopdevopsconsulting
$ hdfs dfs -cat /data/hadoopdevopsconsulting/readme.txt
Delete a file or directory from HDFS directory /data/hadoopdevopsconsulting
$ hdfs dfs -rm /data/hadoopdevopsconsulting/readme.txt
Examples:
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/
Found 1 items
drwxr-xr-x - admin supergroup 0 2016-08-29 11:46 /data/ABC
[admin@hadoopdevopsconsulting ~]# hdfs dfs -mkdir /data/hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/
Found 2 items
drwxr-xr-x - admin supergroup 0 2016-08-29 11:46 /data/ABC
drwxr-xr-x - admin supergroup 0 2016-08-29 11:54 /data/hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -copyFromLocal readme.txt /data/hadoopdevopsconsulting/
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/hadoopdevopsconsulting/
Found 1 items
-rw-r--r-- 2 admin supergroup 57 2016-08-29 11:54 /data/hadoopdevopsconsulting/readme.txt
[admin@hadoopdevopsconsulting ~]# hdfs dfs -cat /data/hadoopdevopsconsulting/readme.txt
Hi This is hadoop command demo by hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -rm /data/hadoopdevopsconsulting/readme.txt
16/08/29 11:55:25 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /data/hadoopdevopsconsulting/readme.txt
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/hadoopdevopsconsulting/
[admin@hadoopdevopsconsulting ~]#
Found 1 items
drwxr-xr-x - admin supergroup 0 2016-08-29 11:46 /data/ABC
[admin@hadoopdevopsconsulting ~]# hdfs dfs -mkdir /data/hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/
Found 2 items
drwxr-xr-x - admin supergroup 0 2016-08-29 11:46 /data/ABC
drwxr-xr-x - admin supergroup 0 2016-08-29 11:54 /data/hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -copyFromLocal readme.txt /data/hadoopdevopsconsulting/
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/hadoopdevopsconsulting/
Found 1 items
-rw-r--r-- 2 admin supergroup 57 2016-08-29 11:54 /data/hadoopdevopsconsulting/readme.txt
[admin@hadoopdevopsconsulting ~]# hdfs dfs -cat /data/hadoopdevopsconsulting/readme.txt
Hi This is hadoop command demo by hadoopdevopsconsulting
[admin@hadoopdevopsconsulting ~]# hdfs dfs -rm /data/hadoopdevopsconsulting/readme.txt
16/08/29 11:55:25 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted /data/hadoopdevopsconsulting/readme.txt
[admin@hadoopdevopsconsulting ~]# hdfs dfs -ls /data/hadoopdevopsconsulting/
[admin@hadoopdevopsconsulting ~]#
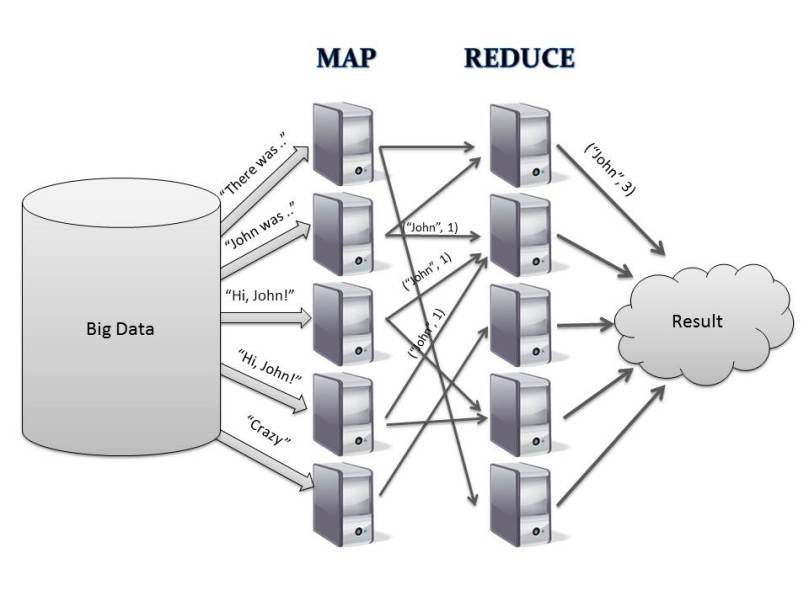
MapReduce:
MapReduce is the algorithm of executing any task on distributed system. Using MapReduce one can process a large file in parallel. MapReduce framework executes any task on different nodes (slaves ) as full file is distributed across the cluster in a form of various blocks.
It has two phases, Map(Mapper Task) and Reduce (Reducer Task)
- Each of these tasks would run on individual blocks of the data
- First mapper task would take each line of elements as an input and generates intermediate key value pairs
- Each mapper task is executed on a single block of data
- Than reducer task will take list of key value pairs for same keys, process the data and generates the final output
- A phase called shuffle and sort will take place between mapper and reducer task will send the data to proper reducer tasks
- Shuffle process maps the mapper output with the same key to the collection of values as a value
- For example (key1, val1) and (key1, val2) will be converted to (key1, [val1, val2])
- The mapper and reducer tasks would in parallel
- The reducer tasks can start their work as soon as mapper tasks are completed



You must be logged in to post a comment.